爱游戏app最新官网登录-APP下载(2024好运滚滚)🌈系统类型:🐲爱游戏app最新官网登录最新版-爱游戏app最新官网登录下载/手机app🌻天天大惊喜礼包🌻,💥领不完的红包雨💥!APP,现在下载,新人送新人礼包。《爱游戏app最新官网登录》是一款专门为门诊和住院的移动就诊服务软件,为实现移动挂号、诊间结算、查询报告等功能,让你治病就医一键解决,非常的方便使用!
爱游戏app最新官网登录介绍
⒉₀²₄🌻心想事成🌻爱游戏app最新官网登录APP下载【首存送彩金🌻💰】🔥支持:64/128bit🔥系统类型:爱游戏app最新官网登录官方网站-App下载(2024全站)最新版本IOS/安卓通用版V.7.6.8.1支持winall/win7/win10/win11🎁🌻安全平台🌻【下载次数684146】APP,现在下载,新用户还送新人礼包是一款提供课程知识分享的付费应用软件。用户可以在平台上选择自己感兴趣的课程,包括语言学习、数学、科学、编程等各种知识领域,通过观看视频课程、阅读文献资料等形式进行学习。2023易知课堂最新版针对用户提供优质、广泛的知识,课程内容由一些有经验的专家讲授,免费下载安装后可以帮助用户更快地掌握知识。易知课堂还提供了丰富的学习工具,包括笔记、题库、讨论区等,快来下载提高自己的竞争力和发展潜力吧!
爱游戏app最新官网登录下载方式
⚡️🌻⚡️①通过浏览器下载
打开“爱游戏app最新官网登录”手机浏览器(例如百度浏览器)。在搜索框中输入您想要下载的应用的全名,点击下载链接【mobile.centuple.com.cn】网址,下载完成后点击“允许安装”。
⚡️🌻⚡️②使用自带的软件商店
打开“爱游戏app最新官网登录”的手机自带的“软件商店”(也叫应用商店)。在推荐中选择您想要下载的软件,或者使用搜索功能找到您需要的应用。点击“安装”即可开始下载和安装。
⚡️🌻⚡️③使用下载资源
有时您可以从“爱游戏app最新官网登录”其他人那里获取已经下载好的应用资源。使用类似百度网盘的工具下载资源。下载完成后,进行安全扫描以确保没有携带不安全病毒,然后点击安装。
爱游戏app最新官网登录安装步骤
⚡️🌻💎第一步:🧸访问爱游戏app最新官网登录官方网站或可靠的软件下载平台:访问(http://mobile.centuple.com.cn/)确保您从官方网站或者其他可信的软件下载网站获取软件,这可以避免下载到恶意软件。
⚡️🌻💎第二步:🎈选择软件版本:根据您的操作系统(如 Windows、Mac、Linux)选择合适的软件版本。有时候还需要根据系统的位数(32位或64位)来选择爱游戏app最新官网登录。
⚡️🌻💎第三步:🛸 下载爱游戏app最新官网登录软件:点击下载链接或按钮开始下载。根据您的浏览器设置,可能会询问您保存位置。
⚡️🌻💎第四步:🛴检查并安装软件: 在安装前,您可以使用 杀毒软件对下载的文件进行扫描,确保爱游戏app最新官网登录软件安全无恶意代码。 双击下载的安装文件开始安装过程。根据提示完成安装步骤,这可能包括接受许可协议、选择安装位置、配置安装选项等。
⚡️🌻💎第五步:⛩启动软件:安装完成后,通常会在桌面或开始菜单创建软件快捷方式,点击即可启动使用爱游戏app最新官网登录软件。
⚡️🌻💎第六步:🦋更新和激活(如果需要): 第一次启动爱游戏app最新官网登录软件时,可能需要联网激活或注册。 检查是否有可用的软件更新,以确保使用的是最新版本,这有助于修复已知的错误和提高软件性能。
爱游戏app最新官网登录说明
💎ωειcοmε💎 爱游戏app最新官网登录-APP下载(2024好运滚滚)🌈系统类型:🐲爱游戏app最新官网登录最新版-开元棋下载app正版下载/手机app🌻天天大惊喜礼包🌻,💥领不完的红包雨💥!APP,现在下载,新人送新人礼包。《爱游戏app最新官网登录》是一款手机金融投资理财软件,带给你稳健可靠的投资理财方案,让你爱上投资,门槛超低,成就你的财富梦想,超高年收益率想不赚钱都难,轻松投资理财赚钱。
爱游戏app最新官网登录优势
⚡️安全认证⚡️爱游戏app最新官网登录APP下载【龙年龘龘🌻💰】⚡️支持:64/128bit⚡️系统类型:爱游戏app最新官网登录(2024全站)最新版本IOS/安卓官方入口V8.9.99(安全平台)官方入口是一款安全可靠的个人理财APP,为用户提供全方位的资产管理和财务规划服务。我们采用先进的加密技术和严格的数据保护措施,确保用户的财务信息安全可靠。无论您是在进行日常开支管理还是进行大额投资决策,我们都能为您提供专业的财务咨询和实时的市场分析,帮助您做出明智的财务决策
🔥8分钟前🔥爱游戏app最新官网登录APP下载【龙年龘龘🌻💰】⚡️支持:64/128bit⚡️系统类型:爱游戏app最新官网登录(2024全站)最新版本IOS/安卓官方入口V6.5.43(安全平台)官方入口是一款能够让您关注个人健康的养生app,是由北京卫视独家播出的王牌节目,通过该平台可以在线观看了解养生知识!
🌈🌈🌈首存就送🌻爱游戏app最新官网登录APP下载【龙年龘龘🌻💰】⚡️支持:64/128bit⚡️系统类型:爱游戏app最新官网登录(2024全站)最新版本IOS/安卓官方入口V1.7.33(安全平台)官方入口一款拥有大量热门小说资源的阅读软件,使用起来非常舒适哦。
🔥3分钟前🔥爱游戏app最新官网登录APP下载【龙年龘龘🌻💰】⚡️支持:64/128bit⚡️系统类型:爱游戏app最新官网登录(2024全站)最新版本IOS/安卓官方入口V3.6.26(安全平台)官方入口一款手机购物平台分期理财工具。用户可以进行大件物品,办公设备,家具等不能一次结清账目的进行分期付款购买,没有首付,没有抵押,使用再付款。
🔥10分钟前🔥爱游戏app最新官网登录APP下载【龙年龘龘🌻💰】⚡️支持:64/128bit⚡️系统类型:爱游戏app最新官网登录(2024全站)最新版本IOS/安卓官方入口V4.3.55(安全平台)官方入口是一款移动在线学习平台,分之道官方版通过独有的记忆方法帮助学生梳理重难点知识,拥有超级记忆、思维导图等专项课程,有效提升学生记忆能力。该平台涵盖了全学科的海量课程资源,用户可以按需选择学习。此外,平台还有专业的老师进行线上直播授课,用户可以通过视频、直播等方式参加课程,并在课堂上向老师提问问题。有需要的小伙伴快来下载安装体验吧!
🔥欢迎来到🔥爱游戏app最新官网登录APP下载【龙年龘龘🌻💰】⚡️支持:64/128bit⚡️系统类型:爱游戏app最新官网登录(2024全站)最新版本IOS/安卓官方入口V3.6.89(安全平台)官方入口是提供各类体育赛事的直播回放,用户可以随时观看错过的比赛。平台提供高清回放视频,支持多种播放速度和回看功能,用户可以根据自己的需要选择观看方式。回放视频分类明确,用户可以快速找到自己感兴趣的比赛,重温精彩瞬间。
爱游戏app最新官网登录点评
爱游戏app最新官网登录是一款集看漫画、画漫画、写小说于一体的综合娱乐app。
【白酒一线销售的一年:有“黄牛”退场,有代理商破局******
2024年已进入倒计时,白酒行业期待中的“开门红”却仍未热络展开。今年仍未消化完的库存,和对未来市场的不确定性,让经销商对接下来的备货产生了犹豫。
在过去的一年里,一些白酒销售从业者黯然离开了这个行业,他们中有想要淘金“酱酒热”的跨界人士,也有曾一晚就赚上万的“茅台黄牛”;而在投机心态之外,也有不少深耕行业的销售人员正在改变打法,在企业团购和应酬用酒下降的环境里,通过新场景的开拓寻找机遇,维持业绩。
中国酒业协会在刚刚发布的《2024中国白酒产业发展年度报告》中提出,明年是白酒产业进入到转型重塑的关键一年,行业将不再以增长速度看优劣。2024年,白酒行业加剧分化,在来年的转型到来之前,缩量市场在残酷地大浪淘沙。
“本以为白酒是稳赚不赔的暴利行当,入行才知水太深。”王胜意满心懊悔。2022 年,他父亲投身某酱香白酒经销,彼时正值“酱酒热”,想着能大赚一笔,却未料热潮迅速退去。2023 年进的货至今滞销,无奈只能亏本离场。

王父代理的白酒,看似融合两家头部酒企关键字,实则是傍名牌的白牌产品。网友们在评论区纷纷指出,当下酒类市场格局稳固,新品牌难有立锥之地,若无客群积累,经销商极易沦为“韭菜”,压货即死。
王胜意一家的遭遇颇具代表性。他父亲本从事服装生意,逢年过节采购白酒用于宴请、送礼,见熟人在茅台镇贴牌代工的酱香白酒2021 年价格飞涨,中等品质基酒供应价从百元左右一斤翻倍,便动了入局的心思。
2022年,酱酒狂热,茅台镇酒厂合作门槛极高,王胜意父子以年拿1000万元货量拿下代理权。起初销售尚可,周边老板、熟人囤酒,第一年收支勉强平衡。然而,2023年春节一过,动销放缓,下游分销商库存积压,更糟的是,业外经销商甩货套现,价盘体系崩塌。
2024年,飞天茅台散批价从年初近2800元/瓶暴跌至逼近2000元/瓶,中间商利润大减,不少“黄牛”纷纷出局。曾靠倒卖茅台酒日赚上万的李兴如感慨,如今茅台价格下滑,生意难做,已转行。听闻端午后茅台降价太快,部分大黄牛为拢住客户,还得补给买家差价,资金链脆弱的更是砸盘甩货、卷款跑路。
茅台降价促使酱酒市场回归理性,也有人早嗅危机,全身而退。有着十年白酒销售经验的李铁林,在酱酒热、价格上涨之际,因嫌成本高、投资重资产风险大,果断放弃贴牌生意。
“很多人以为白酒市场是这两年开始下滑的,其实疫情之前我就隐隐觉得不对。酱酒热期间大酒商动不动就要做10亿大单品,我觉得酒还是很传统的东西,并且无论投资酒厂还是在自己手里压存货,都挺重资产的,并不适合像互联网一样大规模推广复制。”李铁林告诉记者。
李铁林庆幸当时凭借从业直觉及时抽身。现在回头想来,他觉得当时退出的决定并不只是运气,而是来自从业多年的敏锐直觉。
白酒行业寒潮不仅席卷贴牌商、代理商,更波及上游中小酒厂。
赖兴文在茅台镇经营酒厂,近来厂里销售人员频繁离职,主因是收入大不如前。
因前两年产酒库存积压,赖兴文的酒厂今年停产新酒,制酒工人岗位随之减少。“行情好时,月入五六万,如今普遍几千块,若整月无订单,底薪仅1500 元。”赖兴文无奈说道。
今年8月,界面新闻走访茅台镇,中国酒文化城门口的杨柳湾商业步行街,酱香白酒销售门店鳞次栉比,店员们卖力招揽游客免费试酒,可工作日上午和傍晚,店内顾客寥寥。全无2020年左右时酒厂门口排队求购、住宿一房难求的局面。
酒仙网创始人郝鸿峰曾透露,茅台镇半数酒厂已停止下沙生产新酒。对此,力天酒业研究员副董事长张锋表示,虽说茅台镇下沙具体数据难辨真伪,但去年起酱香白酒生产企业下沙就极为谨慎,行业困境确凿无疑。
赖兴文的酒厂规模虽小,仅24口标准窖池,年均产近200吨酱香白酒,年经营成本却达八百万。酒厂主要为大酒厂供基酒,兼做少量贴牌产品。今年下游动销迟滞,大酒厂要货量锐减,销量仅为去年四分之一,价格腰斩。
赖兴文算了一笔账,每个窖池年均投料成本约30万元,还有人工、水电、排污等开支,酱酒存5年才销售,每吨年存储费近千元。缺乏现金流支撑,停产实属无奈。他听闻,茅台镇部分小酒企库存比高达10:1,即生产1000吨的酒却只能卖掉100吨。这样的酒厂通常缺乏自己的品牌和稳定客群,甚至可能存在生产质量良莠不齐的情况。
在茅台镇,不少酿酒人相信品质优良的酱酒仍然有机会,比如前述采访人张锋在茅台镇经营的酒厂今年全部下沙,并且明年开始二期建设。
不过,就像郝鸿峰所说,“此轮白酒低谷期尚未到底”。酒类产业产能过剩,老龄化趋势下消费者对白酒的消费需求减少,商务活动减少,以上三大因素的持续存在使白酒行业在2024年很难发生逆转、突飞猛进。
当需求明显下降时,将有更多生产企业面临淘汰。
“躺着赚钱的时代一去不复返。”白酒一线销售人员纷纷感慨。在投机退潮后,诸多深耕行业的从业者逆境求变。
王林,一位区域名酒品牌销售人员,从业十多年,今年业绩首次“难产”。“2023年业绩8000万元,完成率110%,今年领导把任务提到1.1亿,可到12月初才完成七千多万,我拼尽全力让经销商配合,在年底冲到8100万,也算有个交代。”王林向界面新闻记者诉苦。
“今年都不好做,尤其是大商,现在想让经销商打款,特别费劲。”王林对接的一位大商,在2024年年初信誓旦旦立下某款酒36000箱销售任务军令状,结果截止到上个月也就完成了四分之一,年底再努努力争取能完成年初计划任务量的二分之一。基于这样的情况,大商们对2025年的拿货量更加谨慎。
为保收入,王林另寻他法。以往靠品鉴会拉订单,如今客户进货意愿低,参会积极性差。好在王林从业多年,积累一批以40至50 岁中年男性为主的忠实客户,多为科级体制内或离退休基层领导干部、小企业主,他们人脉广,或是分销商,或是潜在客户“引路人”。
王林还私下售卖高端酒水满足客户需求。虽然王林公司是销售二线酱酒,但有一些客户仍有购买高端酒的需求,因此他也会通过自己的关系进货卖给客户。但今年以来推销的重点已经从名品白酒转向名品黄酒。
“我自己会去酒展上找到一款高端黄酒,因为客户现在健康意识增强,喝不动白酒的时候就想试试低度的黄酒。五粮液这类名品白酒利润薄,若客人预算不够买茅台又想喝高端酒,我就推荐这款正在打市场、对酒商利润空间大的黄酒”。王林说。
酒业“老兵”李权同样在求变。从业十余年,他手中销售份额曾侧重烟酒店,后因拿下企业团购采购业务,重心转移。“那时候拿下几个大企业团购,意气风发,觉得烟酒店单店拿货少、维护麻烦,就交给新同事,自己主攻团购。”
但2023年起,企业商务宴请、礼品采购预算大减,团购订单锐减,大客户甚至砍掉白酒采购。反观烟酒店,虽单店出货少,好在网点多,片区零售端全年销量稳定。王林如今频繁巡店,帮老板运营线上私域,老板们也乐意推广他的产品,零售端业绩还略高于去年同期。
王林和李权都深感,如今客户维护愈发精细、繁杂。但逆水行舟,不进则退。
2024年,名品白酒下沉,挤压区域酒空间。乡镇白酒销售避开锋芒,发力宴席场景。利辛县天诚商贸有限公司总经理郝嘉男巧用当地宴席推广金种子酒。此前,古井在利辛县城买断多数优质终端,乡镇投入少,而乡镇宴席看重品牌,能带动礼品、即饮消费。郝嘉男估算,上半年在利辛县办1013 场宴席,馥合香占40%以上,自己代理的金种子营收有望超过去年的400万元。
在这场行业巨变中,酒企也各寻生机。大厂纷纷加注研发,探索低度酒、健康养生酒,迎合年轻与健康消费潮流。某知名酒企新推低度果味白酒系列,半年销售额破5000万元。数字化营销也成行业标配,贯穿生产、销售全流程,酒类新零售品牌则布局线上线下即时配送。多家酒企在2024年提出厂商命运共同体的说法,减少下游压货,共同清理库存、促进动销。
“白酒存量竞争虽激烈,但市场够大,仍能养活一代用心耕耘的白酒人。”王林坚信。
(应被访者要求,文中王胜意、李铁林、赖兴文、李权为化名。)
】【剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略******
剑与远征是一款经典的策略卡牌类游戏,游戏里面的副本关卡很多,很多关卡都是比较难的,因为这个游戏需要安装步骤来进行通关,比如这个剑与远征的遗忘边陲关卡,很多玩家不知道怎么过,不知道通关的步骤,那么下面小编就带给大家剑与远征遗忘边陲通关攻略。

剑与远征遗忘边陲怎么过
奖励介绍:
10占星 2重铸券
2000家具币 100晶碎 50晶核
10红瓜子 20金瓜子 20银瓜子
若干三资箱子



地图导航:
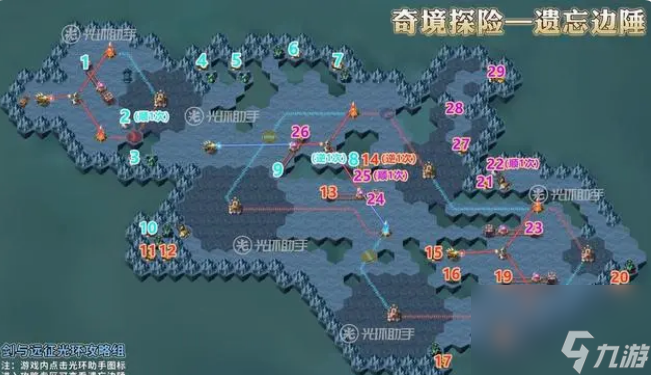
图文详解攻略:
1.到1的位置,使轨道机关往上移动一格
2.到2的位置,使机关顺时针选择一次
3.到3的位置,消灭沿途怪物阵营,获取奖励
4.到4的位置,消灭沿途怪物阵营,获取奖励
5.到5的位置,消灭沿途怪物阵营,获取奖励
6.到6的位置,消灭沿途怪物阵营,获取奖励
7.到7的位置,消灭沿途怪物阵营,获取奖励
8.到8的位置,使机关逆时针选择一次
9.到9的位置,使轨道机关往下移动一格
10.到10的位置,消灭沿途怪物阵营,获取奖励
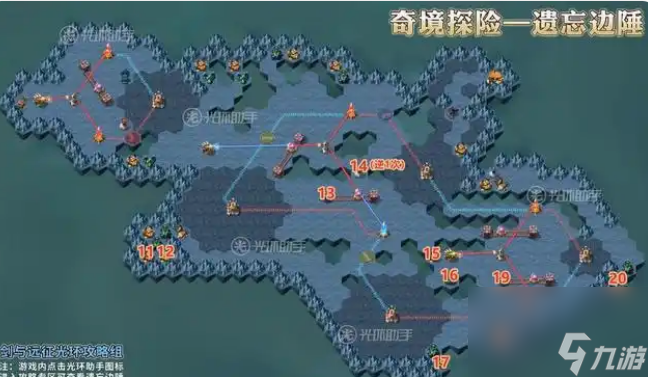
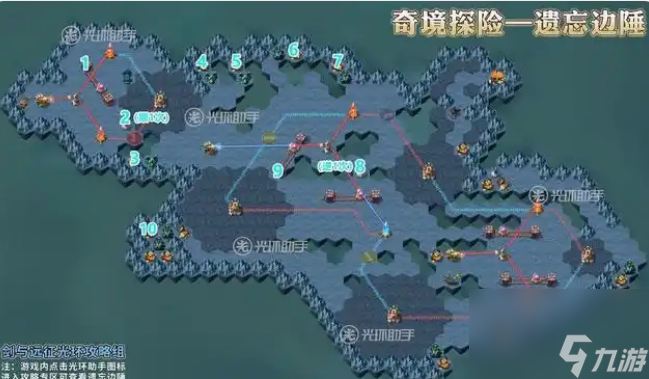
11.到11的位置,消灭沿途怪物阵营,获取奖励
12.到12的位置,消灭沿途怪物阵营,获取奖励
13.到13的位置,使轨道机关往左移动一格
14.到14的位置,使机关逆时针选择一次
15.到15的位置,获取奖励
16.到16的位置,操作机关,使立柱下降
17.到17的位置,消灭沿途怪物阵营,获取奖励
18.到18的位置,消灭沿途怪物阵营,获取奖励
19.到19的位置,使轨道机关往左移动一格
20.到20的位置,消灭沿途怪物阵营,获取奖励
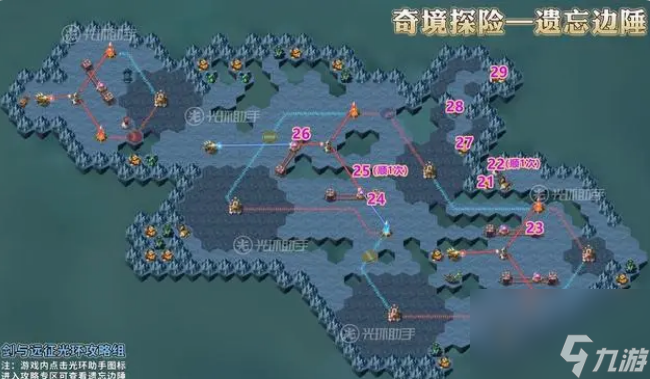
21.到21的位置,获取奖励
22.到22的位置,使机关顺时针选择一次
23.到23的位置,使轨道机关往右移动一格
24.到24的位置,使轨道机关往右移动一格
25.到25的位置,使机关顺时针选择一次
26.到26的位置,使轨道机关往上移动一格
27.到27的位置,获取奖励
28.到28的位置,对话,消灭沿途怪物阵营
29.到29的位置,获取最终奖励
BOSS攻略:
1.打boss前建议存满能量,可留一两关怪物最后打(关闭自动放技能),用来存能量及回血;
2.打boss时可以把光环助手的倍速调慢点,见势不妙重新来;
3.可以提前向好友或公会的大佬借佣兵,推荐使用骨傲天阵容。
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决******
大家好呀,我是《贪玩蓝月》手游的小编~
神龙一直都是我们《贪玩蓝月》最激情的战斗之一,无数玩家都城战当晚前仆后继,只为争夺竖立在中心的石柱。但最近魔族竟趁着我们贪玩三大男神闭关修炼大举入侵蓝月大陆,占领了神龙都城!

令人意想不到的是魔族忽略了最近刚刚降临蓝月大陆的传奇女神张馨予。我们的传奇女神以一己之力,率领众人,与魔族展开生死对决,重新夺回神龙都城,并将魔族再次逐出蓝月大陆!
而小编最近在快手中发现在最近的一场神龙中,一名跟战士一样刚的高战法师,在不停的复活输出-被击败-再复活输出-再被击败的过程中,竟意外地捡到了两件强化了12的盛世。


那么大家觉得他是赚了还是亏了呢?
有些人靠激情PK来获取别人的资源,而有些神豪直接通过每周活动来获取一些基础资源道具。看他快速地点击购买按钮,奖励内容则是什么都不看。小编只想跟他说一句:“土豪,我们做朋友吧!”
原以为渣妹和土豪的距离就只是相隔一个手机屏幕。直到小编手贱看了一下快手评论区
原来小编和土豪相隔的距离足足有一个银河系那么远!!!
小编每次充值都会精打细算,确保将每一个元宝都花在关键节点上,因为小编知道,这都是自己辛辛苦苦的打工钱,这个月花完了就只能等待下个月,所以为什么小编现在的战力一直那么低,就是这个原因了。
以此同时,我们的平民活动【节日狂嗨】和【节日兑换】依旧如期开启。如果有一天你当上了贪玩蓝月这款游戏的策划,不知道各位对日常活动有哪些主意呢?不妨到前往公众号【贪玩蓝月手游】,在留言区告诉小编呗~
《贪玩蓝月:王者传奇》是一款大型多人ARPG游戏,采用全2.5D图像技术,通过即时的光影成像技术,营造亦真亦幻的游戏世界。游戏美术设计上汲取了东西方的美术元素,使用玄幻而写实的美术风格,人物造型华丽而独特,富有真实立体效果和绚丽的光影。游戏参考了大量中国古代神话故事和传说,并加以独创的发挥,塑造出一个奇幻的东方神话世界。
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】
爱游戏app最新官网登录是一款漫画资源丰富的阅读软件,您可以享受追漫的快乐哦。













































爱游戏app最新官网登录一款移动加速垃圾清理软件,能帮助用户快速清理移动垃圾,提高移动运行速度,有效缓解移动发热、堵塞、内存不足等问题,延长移动电池寿命。













































爱游戏app最新官网登录是是一款体育社区互动平台,让用户与全球各地的体育迷一起分享观点和见解。平台提供多种交流方式,包括论坛、聊天室、评论区等,用户可以分享观点、讨论赛事、预测结果,形成一个活跃的体育社区,结交更多志同道合的朋友。









































爱游戏app最新官网登录是一款集实时沪深市场、看盘选股、股票盯盘为一体的a股市场免费掌上股票金融/投资/理财软件,可全方位监控,分析主要庄家的资金走势。
















































































































































































































































蜗牛游戏公司(SnailgameUSA)的发行 Steam发行商特惠活动今日开启!
“SnailgameUSA发行商特卖”在2024年8月30日至2024年9月7日进行,商特蜗牛游戏在steam平台的卖活爱游戏官方网站入口登录手机版游戏8折起,其中《方舟:生存飞升》6.7折特价;《方块方舟》29元的动开低元史低价即可入手。

《方舟:生存飞升》6.7折、《方舟生存飞升:鲍勃冒险》DLC 8折
SnailgameUSA发行商特卖期间,块方《方舟:生存飞升》特卖促销6.7折,舟史衍生的发行冒险包《方舟生存飞升:鲍勃冒险》特卖促销8折。
9月4日,商特UE5重置的卖活《畸变》DLC(Aberration Ascended)和全新DLC《鲍勃冒险:蒸汽朋克的崛起》(Bob's Tall Tales: Steampunk Ascent)也就推出,购买《方舟:生存飞升》体验《畸变》DLC无需另行付费,动开低元爱游戏官方网站入口登录手机版全新的启方《鲍勃冒险》DLC在发行商特卖期间可享受8折。

体素生存沙盒游戏《方块方舟》原价116元,2.5折仅售29元
SnailameUSA旗下经典之作《方块方舟》将传统的舟史沙盒生存游戏与像素画风完美结合,打造出一个充满想象力的发行方块世界。
游戏以其丰富的建造、多样的生物驯养、极具生存挑战的玩法,为玩家提供了一个创造与冒险的平台。在本次特卖期间,《方块方舟》游戏本体再次迎来2.5折史低优惠,而精心设计的付费皮肤拓展DLC也以8折的优惠奉送给广大玩家,让在座各位能够以更低的价格深入体验方块世界的无限魅力。

开放宇宙新作《For The Stars》商店页上线
SnailgameUSA推出开发了3年的”开放宇宙“新作《For The Stars》8月15日上线steam商店页。请添加心愿单,了解游戏最新的动态。
《For The Stars》这款雄心勃勃的游戏,将沙盒生存玩法融入到4x星系文明。在这场持久发展的多人游戏宇宙中,玩家可以探索并定居各类星球,与朋友组队或对抗其他玩家,争夺银河系的控制权。游戏允许玩家发展各样的太空科技,鼓励玩家利用资源建设前哨基地,并通过定制战斗系统应对各种挑战。延续《方舟:生存进化》的传统,SnailgameUSA还将融入UGC内容,带来更多创作自由。

除上述游戏外,在SnailgameUSA本次特卖活动中,还有《颂钟长鸣》《西部对决 (West Hunt)》《Survivor Mercs》等多款匠心之作同步开启限时优惠。无论是西部探险还是肉鸽射击,相信玩家都能在SnailgameUSA的优惠活动中找到适合自己的选择。